



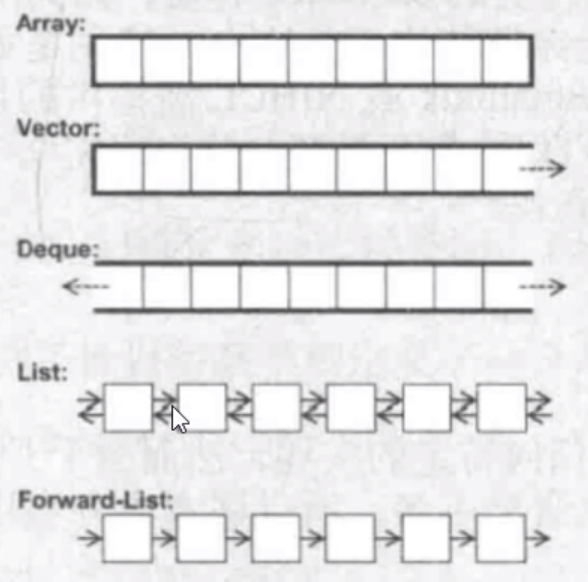
容器的分类
1)顺序容器:放进去在那里,这个元素就在那里,比如array,vector,deque,list,forward_list。各个容器的示意图如下
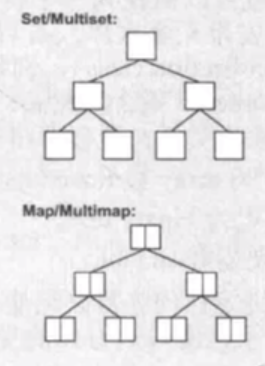
2)关联容器:元素是键值对,特别适合做查找,能控制插入的内容,但是不能控制插入的位置,比如说set,multiset,map,multimap,hash_set,hash_map
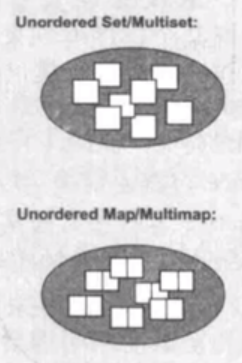
3)无序容器:c++11推出,元素的位置不重要,重要的是元素是否存在在这个容器中。无序容器也可以认为是一种关联容器,比如说unordered_set,unordered_multiset,unordered_map,unordered_multimap
c++标准并没有规定任何容器必须使用特定的实现手段
array
是个顺序容器,其实是个数组,内存空间是连续的,大小是固定的,刚开始申请的时候是多大,就是多大,不能动态增加减少
vector
从后面添加或者删除元素容易,往中间插入或删除元素效率低;查找速度不快。
vector容器内存也是挨着的,容器中有多少个元素可以用size()来看,而这个容器有多少空间可以用capacity()来看;capacity()一定不会小于size()。可以使用reserve()来预留空间
deque
双端队列,相当于动态数组,头部尾部插入删除数据都很快,中间插入删除元素效率低。
内存是分段连续的
stack
栈,后进先出。与vector相比,vector支持从中间插入或删除,stack不支持从中间插入和删除,只能操作栈顶。deque实际上包含着stack的功能
queue
队列,先进先出。只能从一段入队,从另一端出队。deque实际上也包含着queue的功能
list
双向链表,不需要各个元素之间的内存连在一起,查找效率低,在任意位置插入或删除效率高。vector和list的区别
1)vector类似于数组,它的内存空间是连续的;list双向链表,内存空间并不连续
2)vector从中间或者开头插入数据效率低;list插入删除元素效率高
3)vector当内存不够时,会重新找一块内存,对原来的内存对象做析构,在新的内存中重新构建对象
4)vector能够高效的随机存取,而list做不到这一点。vector可以直接用下标访问,list只能从头开始。
forward_list
c++11新加,单向列表,少了一个方向指针,但是节省内存
set/map
关联容器,内部实现多为红黑树,往这种容器中保存数据时,不需要指定位置,会自动调整位置。
map:每个元素有两项,键值对;一般通过key找value,速度非常快;不允许key相同,如果非要让key相同,使用multimap
map<int,string> mymap;
mymap.insert(std::make_pair(1,"john"));
mymap.insert(pair<int, string>(2,"lily"));
mymap.insert(pair<int, string>(2,"ally")); // 键相同,则这句没用
auto iter = mymap.find(2);
set:每个元素就是一个value,元素值不能重复,如果想要重复,使用multiset
总结:
1)插入时,容器要找到一个插入的位置,所以插入的速度可能会慢
2)查找的速度快
unordered_set,unordered_multiset,unordered_map,unordered_multimap
以往的hash_set,hash_map等老版本容器,不推荐使用;应该使用unordered开头的容器
unordered_set<int> myset;
cout<<myset.bucket_count()<<endl; //系统初始时,有8个,存满时会扩容
//max_bucket_count()可以查看最大数量
优先使用容器里自带的find()函数,如果没有,可以使用全局的find()函数
分配器
和容器紧密相联,一起使用。确切地说,内存分配器,扮演内存池的角色,通过大量减少对malloc()的调用,来节省内存,甚至还有一定的分配效率的提高;经过测验,allocator没有采用内存池的工作机制
list<int> mylist;
list<int, std::allocator<int>> mylist; //这两句等价
迭代器
迭代器是一个可遍历stl容器全部或者部分元素的对象,迭代器用于表现容器中的某一个位置,迭代器紧密依赖于容器,一般来说是容器里面定义着迭代器的具体类型细节。
vector<int> iv = {100,200,300};
for(vector<int>::iterator iter = iv.begin();iter!=iv.end();iter++)
{
cout<<*iter<<endl;
}
迭代器的分类
依据是迭代器的移动特性以及在这个迭代器上能够做的操作;我们一般分类是依据迭代器的跳跃能力,每个分类是一个对应的struct定义。大多数容器中都有迭代器,并不是所有容器都有迭代器,stack和queue就没有
输出型迭代器:对应struct output_iterator_tag,一步一步往前走,并且能够这种迭代器来改写容器中的数据;支持*iter,iter++,++iter
输入型迭代器:对应struct input_iterator_tag,一次一个以向前的方向读取元素,安装顺序一个一个返回元素值;支持*iter,iter++,++iter,iter->成员变量,iter1==iter2,iter1!=iter2
前向型迭代器:对应struct forward_iterator_tag,继承input_iterator_tag,它能以向前的方式读取元素,并且读取时提供额外保证,在输入迭代器基础上增加了iter1 = iter2赋值操作。容器为forward list, unordered containers
双向迭代器:对应struct bidirectional_iterator_tag,继承forward_iterator_tag ,增加了反向迭代,在前向迭代器的基础上增加了iter--,--iter操作。容器为list, set, multiset, map, multimap
随机访问迭代器:对应struct random_access_iterator_tag,继承bidirectional_iterator_tag,在双向迭代器的基础上增加了随机访问能力,还支持一些关系运算,支持iter[n], iter += n, iter -= n,iter + n, iter - n, iter1 - iter2, iter1 </>/<=/>= iter2。容器为array, vector, deque, string, C style array
算法
stl的算法为函数模板,包含查找,排序等,算法为全局函数模板,需要添加#include<algorithm>。算法的前两个形参类型,一般都是迭代器类型,用来表示容器中元素的区间,这个区间前闭后开。算法会根据传进来的迭代器分析出迭代器种类,不同种类的迭代器算法会有不同的处理,要编写不同的代码来应对。
常用算法
for_each()
void myfunc(int i)
{
cout<<i<<endl;
}
vector<int> myvec = {1,2,3,4,5};
for_each(myvec.begin(),myvec.end(),myfunc); //第三个参数为可调用对象
//输出1,2,3,4,5
find()
vector<int> myvec = {1,2,3,4,5};
vector<int>::iterator finditer = find(myvec.begin(),myvec.end(),400);
if(finditer != myvec.end()) //判断是否等于find()中的第二个参数,等于就是没找到,不等于就是找到了
{
//找到了
}else{
//没找到
}
sort()
vector<int> myvec = {3,1,4,2,5};
sort(myvec.begin(),myvec.end());
for(auto iter = myvec.begin();iter != myvec.end(),iter++){
cout<<*iter<<endl; //默认从小到大排序
}
若要从大到小排序,我们可以写自定义的比较函数,这个函数是返回bool
bool myfunc(int i,int j){
//return i<j; //从小到大排序
return i>j; //从小到大排序
}
vector<int> myvec = {3,1,4,2,5};
sort(myvec.begin(),myvec.end(),myfunc);
for(auto iter = myvec.begin();iter != myvec.end(),iter++){
cout<<*iter<<endl; //从大到小排序
}
list不支持sort()算法,有自己的排序算法
函数对象/仿函数
函数对象在stl中,一般都是和算法配合来使用的,从而实现一些特定的功能,这些函数对象主要服务于算法。
函数对象主要有:
1)函数:void func(int x){…};
2)可调用对象:class A{public:void operator()(int x){…}};
3)lambda表达式:[](int x){…};
标准库中定义的函数对象,可以直接使用,使用需要添加#include<functional>

vector<int> myvec = {3,1,4,2,5};
sort(myvec.begin(),myvec.end(),greater<int>());
for(auto iter = myvec.begin();iter != myvec.end(),iter++){
cout<<*iter<<endl; //从大到小排序
}
适配器
把一个既有的东西进行适当的改造,比如说增加点东西,或者减少点东西,就构成了一个适配器
容器适配器
stack和queue是阉割版的deque,所以这两个就可以称为适配器
算法适配器
也可以叫作函数适配器,最典型的就是绑定器
老版本bind1st,bind2nd;在c++11中,名字被修改为bind。
参考网站:cppreference.com
vector<int> myvec = {3,1,4,2,5,4};
int cnt = count(myvec.begin(),myvec.end(),4); //算法,统计某个值的出现次数
cout<<cnt<<endl; //2
class A
{
public:
bool operator()(int i){
return i>3;
}
};
vector<int> myvec = {3,1,4,2,5,4};
A myobj;
int cnt = count(myvec.begin(),myvec.end(),myobj); //算法,统计某个值的出现次数
cout<<cnt<<endl; //3
bind(less<int>,40,placeholders::_1);
//less<int>的operator()的第一个参数绑定为40,那这样当调用less<int>()这个可调用对象时,只需要提供第二个参数
//第一个参数placeholders::_1被40取代
vector<int> myvec = {3,1,4,2,5,4};
int cnt = count(myvec.begin(),myvec.end(),bind(less<int>,3,placeholders::_1));
cout<<cnt<<endl; //3
迭代器适配器
reverse_iterator,反向迭代器
评论区